class: center, middle, inverse, title-slide # Wrangle data <br> 🤠 --- layout: true <div class="my-footer"> <span> <a href="https://rstd.io/bootcamper" target="_blank">rstd.io/bootcamper</a> </span> </div> --- ## A grammar of data wrangling... ... based on the concepts of functions as verbs that manipulate data frames .pull-left[ <img src="img/dplyr-part-of-tidyverse.png" width="80%" style="display: block; margin: auto;" /> ] .pull-right[ .midi[ - `select`: pick columns by name - `arrange`: reorder rows - `slice`: pick rows using index(es) - `filter`: pick rows matching criteria - `distinct`: filter for unique rows - `mutate`: add new variables - `summarise`: reduce variables to values - `group_by`: for grouped operations - ... (many more) ] ] --- ## Rules of **dplyr** functions - First argument is *always* a data frame - Subsequent arguments say what to do with that data frame - Always return a data frame - Don't modify in place --- ## Data: Hotel bookings - Data from two hotels: one resort and one city hotel - Observations: Each row represents a hotel booking - Goal for original data collection: Development of prediction models to classify a hotel booking's likelihood to be cancelled ([Antonia et al., 2019](https://www.sciencedirect.com/science/article/pii/S2352340918315191#bib5)) - Featured in [TidyTuesday](https://github.com/rfordatascience/tidytuesday)! ```r hotels <- read_csv("data/hotels.csv") ``` --- ## First look: Variables ```r names(hotels) ``` ``` ## [1] "hotel" "is_canceled" ## [3] "lead_time" "arrival_date_year" ## [5] "arrival_date_month" "arrival_date_week_number" ## [7] "arrival_date_day_of_month" "stays_in_weekend_nights" ## [9] "stays_in_week_nights" "adults" ## [11] "children" "babies" ## [13] "meal" "country" ## [15] "market_segment" "distribution_channel" ## [17] "is_repeated_guest" "previous_cancellations" ## [19] "previous_bookings_not_canceled" "reserved_room_type" ## [21] "assigned_room_type" "booking_changes" ## [23] "deposit_type" "agent" ## [25] "company" "days_in_waiting_list" ## [27] "customer_type" "adr" ## [29] "required_car_parking_spaces" "total_of_special_requests" ## [31] "reservation_status" "reservation_status_date" ``` --- ## Second look: Overview .xxsmall[ ```r glimpse(hotels) ``` ``` ## Rows: 119,390 ## Columns: 32 ## $ hotel <chr> "Resort Hotel", "Resort Hotel", "Resort Hotel", "Resort Ho… ## $ is_canceled <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0… ## $ lead_time <dbl> 342, 737, 7, 13, 14, 14, 0, 9, 85, 75, 23, 35, 68, 18, 37,… ## $ arrival_date_year <dbl> 2015, 2015, 2015, 2015, 2015, 2015, 2015, 2015, 2015, 2015… ## $ arrival_date_month <chr> "July", "July", "July", "July", "July", "July", "July", "J… ## $ arrival_date_week_number <dbl> 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27… ## $ arrival_date_day_of_month <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1… ## $ stays_in_weekend_nights <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0… ## $ stays_in_week_nights <dbl> 0, 0, 1, 1, 2, 2, 2, 2, 3, 3, 4, 4, 4, 4, 4, 4, 4, 1, 1, 4… ## $ adults <dbl> 2, 2, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2… ## $ children <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0… ## $ babies <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0… ## $ meal <chr> "BB", "BB", "BB", "BB", "BB", "BB", "BB", "FB", "BB", "HB"… ## $ country <chr> "PRT", "PRT", "GBR", "GBR", "GBR", "GBR", "PRT", "PRT", "P… ## $ market_segment <chr> "Direct", "Direct", "Direct", "Corporate", "Online TA", "O… ## $ distribution_channel <chr> "Direct", "Direct", "Direct", "Corporate", "TA/TO", "TA/TO… ## $ is_repeated_guest <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0… ## $ previous_cancellations <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0… ## $ previous_bookings_not_canceled <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0… ## $ reserved_room_type <chr> "C", "C", "A", "A", "A", "A", "C", "C", "A", "D", "E", "D"… ## $ assigned_room_type <chr> "C", "C", "C", "A", "A", "A", "C", "C", "A", "D", "E", "D"… ## $ booking_changes <dbl> 3, 4, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0… ## $ deposit_type <chr> "No Deposit", "No Deposit", "No Deposit", "No Deposit", "N… ## $ agent <chr> "NULL", "NULL", "NULL", "304", "240", "240", "NULL", "303"… ## $ company <chr> "NULL", "NULL", "NULL", "NULL", "NULL", "NULL", "NULL", "N… ## $ days_in_waiting_list <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0… ## $ customer_type <chr> "Transient", "Transient", "Transient", "Transient", "Trans… ## $ adr <dbl> 0.00, 0.00, 75.00, 75.00, 98.00, 98.00, 107.00, 103.00, 82… ## $ required_car_parking_spaces <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0… ## $ total_of_special_requests <dbl> 0, 0, 0, 0, 1, 1, 0, 1, 1, 0, 0, 0, 3, 1, 0, 3, 0, 0, 0, 1… ## $ reservation_status <chr> "Check-Out", "Check-Out", "Check-Out", "Check-Out", "Check… ## $ reservation_status_date <date> 2015-07-01, 2015-07-01, 2015-07-02, 2015-07-02, 2015-07-0… ``` ] --- ## Select a single column View only the `lead_time` type (number of days between booking and arrival date): -- .pull-left[ ```r select(.data = hotels, lead_time) ``` ``` ## # A tibble: 119,390 x 1 ## lead_time ## <dbl> ## 1 342 ## 2 737 ## 3 7 ## 4 13 ## 5 14 ## 6 14 ## # … with 119,384 more rows ``` ] -- .pull-right[ - Start with the function (a verb): `select()` - First argument is `.data` (the data frame we're working with) = `hotels` - Second argument is variable we want to select: `lead_time` - The result is a data frame with 119,300 and 1 column: --dplyr functions always expect a data frame and always yield a data frame. ] --- .tip[ You can skip the argument name for the first two arguments of a function. ] .pull-left[ ```r select(.data = hotels, lead_time) ``` ``` ## # A tibble: 119,390 x 1 ## lead_time ## <dbl> ## 1 342 ## 2 737 ## 3 7 ## 4 13 ## 5 14 ## 6 14 ## # … with 119,384 more rows ``` ] .pull-right[ ```r select(hotels, lead_time) ``` ``` ## # A tibble: 119,390 x 1 ## lead_time ## <dbl> ## 1 342 ## 2 737 ## 3 7 ## 4 13 ## 5 14 ## 6 14 ## # … with 119,384 more rows ``` ] --- ## Select multiple columns View only the `hotel` type and `lead_time`: -- .pull-left[ ```r select(hotels, hotel, lead_time) ``` ``` ## # A tibble: 119,390 x 2 ## hotel lead_time ## <chr> <dbl> ## 1 Resort Hotel 342 ## 2 Resort Hotel 737 ## 3 Resort Hotel 7 ## 4 Resort Hotel 13 ## 5 Resort Hotel 14 ## 6 Resort Hotel 14 ## # … with 119,384 more rows ``` ] -- .pull-right[ .discussion[ What if we wanted to select these columns, and then arrange the data in descending order of lead time? ] ] --- ## Data wrangling, step-by-step .pull-left[ Select: ```r hotels %>% select(hotel, lead_time) ``` ``` ## # A tibble: 119,390 x 2 ## hotel lead_time ## <chr> <dbl> ## 1 Resort Hotel 342 ## 2 Resort Hotel 737 ## 3 Resort Hotel 7 ## 4 Resort Hotel 13 ## 5 Resort Hotel 14 ## 6 Resort Hotel 14 ## # … with 119,384 more rows ``` ] -- .pull-right[ Select, then arrange: ```r hotels %>% select(hotel, lead_time) %>% arrange(desc(lead_time)) ``` ``` ## # A tibble: 119,390 x 2 ## hotel lead_time ## <chr> <dbl> ## 1 Resort Hotel 737 ## 2 Resort Hotel 709 ## 3 City Hotel 629 ## 4 City Hotel 629 ## 5 City Hotel 629 ## 6 City Hotel 629 ## # … with 119,384 more rows ``` ] --- class: middle # Pipes --- ## What is a pipe? In programming, a pipe is a technique for passing information from one process to another. -- .pull-left[ - Start with the data frame `hotels`, and pass it to the `select()` function, ] .pull-right[ .small[ ```r *hotels %>% select(hotel, lead_time) %>% arrange(desc(lead_time)) ``` ``` ## # A tibble: 119,390 x 2 ## hotel lead_time ## <chr> <dbl> ## 1 Resort Hotel 737 ## 2 Resort Hotel 709 ## 3 City Hotel 629 ## 4 City Hotel 629 ## 5 City Hotel 629 ## 6 City Hotel 629 ## # … with 119,384 more rows ``` ] ] --- ## What is a pipe? In programming, a pipe is a technique for passing information from one process to another. .pull-left[ - Start with the data frame `hotels`, and pass it to the `select()` function, - then we select the variables `hotel` and `lead_time`, ] .pull-right[ .small[ ```r hotels %>% * select(hotel, lead_time) %>% arrange(desc(lead_time)) ``` ``` ## # A tibble: 119,390 x 2 ## hotel lead_time ## <chr> <dbl> ## 1 Resort Hotel 737 ## 2 Resort Hotel 709 ## 3 City Hotel 629 ## 4 City Hotel 629 ## 5 City Hotel 629 ## 6 City Hotel 629 ## # … with 119,384 more rows ``` ] ] --- ## What is a pipe? In programming, a pipe is a technique for passing information from one process to another. .pull-left[ - Start with the data frame `hotels`, and pass it to the `select()` function, - then we select the variables `hotel` and `lead_time`, - and then we arrange the data frame by `lead_time` in descending order. ] .pull-right[ .small[ ```r hotels %>% select(hotel, lead_time) %>% * arrange(desc(lead_time)) ``` ``` ## # A tibble: 119,390 x 2 ## hotel lead_time ## <chr> <dbl> ## 1 Resort Hotel 737 ## 2 Resort Hotel 709 ## 3 City Hotel 629 ## 4 City Hotel 629 ## 5 City Hotel 629 ## 6 City Hotel 629 ## # … with 119,384 more rows ``` ] ] --- ## Aside The pipe operator is implemented in the package **magrittr**, though we don't need to load this package explicitly since **tidyverse** does this for us. -- .discussion[ Any guesses as to why the package is called magrittr? ] -- .pull-left[ <img src="img/magritte.jpg" width="100%" style="display: block; margin: auto;" /> ] .pull-right[ <img src="img/magrittr.jpg" width="100%" style="display: block; margin: auto;" /> ] --- ## How does a pipe work? - You can think about the following sequence of actions - find key, unlock car, start car, drive to work, park. -- - Expressed as a set of nested functions in R pseudocode this would look like: ```r park(drive(start_car(find("keys")), to = "work")) ``` -- - Writing it out using pipes give it a more natural (and easier to read) structure: ```r find("keys") %>% start_car() %>% drive(to = "work") %>% park() ``` --- ## What about other arguments? Use the dot to - send results to a function argument other than first one or - use the previous result for multiple arguments ```r hotels %>% filter(hotel == "Resort Hotel") %>% * lm(adr ~ lead_time, data = .) ``` ``` ## ## Call: ## lm(formula = adr ~ lead_time, data = .) ## ## Coefficients: ## (Intercept) lead_time ## 93.16876 0.01925 ``` --- ## A note on piping and layering - The `%>%` operator in **dplyr** functions is called the pipe operator. This means you "pipe" the output of the previous line of code as the first input of the next line of code. -- - The `+` operator in **ggplot2** functions is used for "layering". This means you create the plot in layers, separated by `+`. --- ## dplyr .midi[ ❌ ```r hotels + select(hotel, lead_time) ``` ``` ## Error in select(hotel, lead_time): object 'hotel' not found ``` ✅ ```r hotels %>% select(hotel, lead_time) ``` ``` ## # A tibble: 119,390 x 2 ## hotel lead_time ## <chr> <dbl> ## 1 Resort Hotel 342 ## 2 Resort Hotel 737 ## 3 Resort Hotel 7 ## 4 Resort Hotel 13 ## 5 Resort Hotel 14 ## 6 Resort Hotel 14 ## # … with 119,384 more rows ``` ] --- ## ggplot2 .midi[ ❌ ```r ggplot(hotels, aes(x = hotel, fill = deposit_type)) %>% geom_bar() ``` ``` ## Error: `mapping` must be created by `aes()` ## Did you use %>% instead of +? ``` ✅ ```r ggplot(hotels, aes(x = hotel, fill = deposit_type)) + geom_bar() ``` 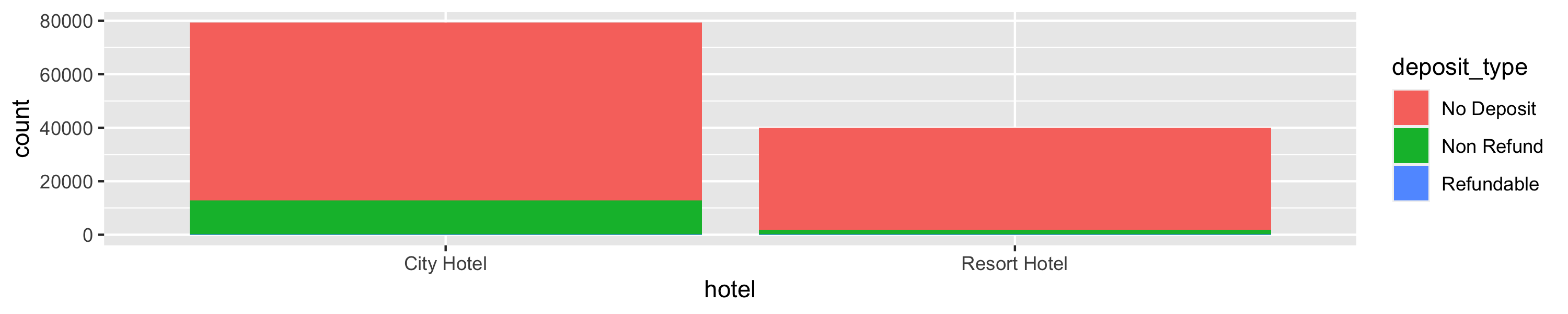<!-- --> ] --- ## Code styling Many of the styling principles are consistent across `%>%` and `+`: - always a space before - always a line break after (for pipelines with more than 2 lines) ❌ ```r ggplot(hotels,aes(x=hotel,y=deposit_type))+geom_bar() ``` ✅ ```r ggplot(hotels, aes(x = hotel, y = deposit_type)) + geom_bar() ``` --- class: middle # Working with a single data frame --- class: middle .hand[You...] .huge-blue[have] .hand[a single data frame] .huge-pink[want] .hand[to slice it, and dice it, and juice it, and process it] --- ## `select` to keep variables ```r hotels %>% * select(hotel, lead_time) ``` ``` ## # A tibble: 119,390 x 2 ## hotel lead_time ## <chr> <dbl> ## 1 Resort Hotel 342 ## 2 Resort Hotel 737 ## 3 Resort Hotel 7 ## 4 Resort Hotel 13 ## 5 Resort Hotel 14 ## 6 Resort Hotel 14 ## # … with 119,384 more rows ``` --- ## `select` to exclude variables .small[ ```r hotels %>% * select(-agent) ``` ``` ## # A tibble: 119,390 x 31 ## hotel is_canceled lead_time arrival_date_ye… arrival_date_mo… arrival_date_we… arrival_date_da… ## <chr> <dbl> <dbl> <dbl> <chr> <dbl> <dbl> ## 1 Reso… 0 342 2015 July 27 1 ## 2 Reso… 0 737 2015 July 27 1 ## 3 Reso… 0 7 2015 July 27 1 ## 4 Reso… 0 13 2015 July 27 1 ## 5 Reso… 0 14 2015 July 27 1 ## 6 Reso… 0 14 2015 July 27 1 ## # … with 119,384 more rows, and 24 more variables: stays_in_weekend_nights <dbl>, ## # stays_in_week_nights <dbl>, adults <dbl>, children <dbl>, babies <dbl>, meal <chr>, ## # country <chr>, market_segment <chr>, distribution_channel <chr>, is_repeated_guest <dbl>, ## # previous_cancellations <dbl>, previous_bookings_not_canceled <dbl>, reserved_room_type <chr>, ## # assigned_room_type <chr>, booking_changes <dbl>, deposit_type <chr>, company <chr>, ## # days_in_waiting_list <dbl>, customer_type <chr>, adr <dbl>, required_car_parking_spaces <dbl>, ## # total_of_special_requests <dbl>, reservation_status <chr>, reservation_status_date <date> ``` ] --- ## `select` a range of variables ```r hotels %>% * select(hotel:arrival_date_month) ``` ``` ## # A tibble: 119,390 x 5 ## hotel is_canceled lead_time arrival_date_year arrival_date_month ## <chr> <dbl> <dbl> <dbl> <chr> ## 1 Resort Hotel 0 342 2015 July ## 2 Resort Hotel 0 737 2015 July ## 3 Resort Hotel 0 7 2015 July ## 4 Resort Hotel 0 13 2015 July ## 5 Resort Hotel 0 14 2015 July ## 6 Resort Hotel 0 14 2015 July ## # … with 119,384 more rows ``` --- ## `select` variables with certain characteristics ```r hotels %>% * select(starts_with("arrival")) ``` ``` ## # A tibble: 119,390 x 4 ## arrival_date_year arrival_date_month arrival_date_week_number arrival_date_day_of_month ## <dbl> <chr> <dbl> <dbl> ## 1 2015 July 27 1 ## 2 2015 July 27 1 ## 3 2015 July 27 1 ## 4 2015 July 27 1 ## 5 2015 July 27 1 ## 6 2015 July 27 1 ## # … with 119,384 more rows ``` --- ## `select` variables with certain characteristics ```r hotels %>% * select(ends_with("type")) ``` ``` ## # A tibble: 119,390 x 4 ## reserved_room_type assigned_room_type deposit_type customer_type ## <chr> <chr> <chr> <chr> ## 1 C C No Deposit Transient ## 2 C C No Deposit Transient ## 3 A C No Deposit Transient ## 4 A A No Deposit Transient ## 5 A A No Deposit Transient ## 6 A A No Deposit Transient ## # … with 119,384 more rows ``` --- ## Select helpers - `starts_with()`: Starts with a prefix - `ends_with()`: Ends with a suffix - `contains()`: Contains a literal string - `num_range()`: Matches a numerical range like x01, x02, x03 - `one_of()`: Matches variable names in a character vector - `everything()`: Matches all variables - `last_col()`: Select last variable, possibly with an offset - `matches()`: Matches a regular expression (a sequence of symbols/characters expressing a string/pattern to be searched for within text) .footnote[ See help for any of these functions for more info, e.g. `?everything`. ] --- ## `arrange` in ascending / descending order .pull-left[ ```r hotels %>% select(adults, children, babies) %>% * arrange(babies) ``` ``` ## # A tibble: 119,390 x 3 ## adults children babies ## <dbl> <dbl> <dbl> ## 1 2 0 0 ## 2 2 0 0 ## 3 1 0 0 ## 4 1 0 0 ## 5 2 0 0 ## 6 2 0 0 ## # … with 119,384 more rows ``` ] .pull-right[ ```r hotels %>% select(adults, children, babies) %>% * arrange(desc(babies)) ``` ``` ## # A tibble: 119,390 x 3 ## adults children babies ## <dbl> <dbl> <dbl> ## 1 2 0 10 ## 2 1 0 9 ## 3 2 0 2 ## 4 2 0 2 ## 5 2 0 2 ## 6 2 0 2 ## # … with 119,384 more rows ``` ] --- ## `slice` for certain row numbers .midi[ ```r # first five hotels %>% * slice(1:5) ``` ``` ## # A tibble: 5 x 32 ## hotel is_canceled lead_time arrival_date_ye… arrival_date_mo… arrival_date_we… arrival_date_da… ## <chr> <dbl> <dbl> <dbl> <chr> <dbl> <dbl> ## 1 Reso… 0 342 2015 July 27 1 ## 2 Reso… 0 737 2015 July 27 1 ## 3 Reso… 0 7 2015 July 27 1 ## 4 Reso… 0 13 2015 July 27 1 ## 5 Reso… 0 14 2015 July 27 1 ## # … with 25 more variables: stays_in_weekend_nights <dbl>, stays_in_week_nights <dbl>, ## # adults <dbl>, children <dbl>, babies <dbl>, meal <chr>, country <chr>, market_segment <chr>, ## # distribution_channel <chr>, is_repeated_guest <dbl>, previous_cancellations <dbl>, ## # previous_bookings_not_canceled <dbl>, reserved_room_type <chr>, assigned_room_type <chr>, ## # booking_changes <dbl>, deposit_type <chr>, agent <chr>, company <chr>, ## # days_in_waiting_list <dbl>, customer_type <chr>, adr <dbl>, required_car_parking_spaces <dbl>, ## # total_of_special_requests <dbl>, reservation_status <chr>, reservation_status_date <date> ``` ] --- .tip[ In R, you can use the `#` (hashtag or pound sign, depending on your age 😜) for adding comments to your code. Any text following `#` will be printed as is, and won't be run as R code. This is useful for leaving comments in your code and for temporarily disabling certain lines of code while debugging. ] .small[ ```r hotels %>% # slice the first five rows # this line is a comment #select(hotel) %>% # this one doesn't run slice(1:5) # this line runs ``` ``` ## # A tibble: 5 x 32 ## hotel is_canceled lead_time arrival_date_ye… arrival_date_mo… arrival_date_we… arrival_date_da… ## <chr> <dbl> <dbl> <dbl> <chr> <dbl> <dbl> ## 1 Reso… 0 342 2015 July 27 1 ## 2 Reso… 0 737 2015 July 27 1 ## 3 Reso… 0 7 2015 July 27 1 ## 4 Reso… 0 13 2015 July 27 1 ## 5 Reso… 0 14 2015 July 27 1 ## # … with 25 more variables: stays_in_weekend_nights <dbl>, stays_in_week_nights <dbl>, ## # adults <dbl>, children <dbl>, babies <dbl>, meal <chr>, country <chr>, market_segment <chr>, ## # distribution_channel <chr>, is_repeated_guest <dbl>, previous_cancellations <dbl>, ## # previous_bookings_not_canceled <dbl>, reserved_room_type <chr>, assigned_room_type <chr>, ## # booking_changes <dbl>, deposit_type <chr>, agent <chr>, company <chr>, ## # days_in_waiting_list <dbl>, customer_type <chr>, adr <dbl>, required_car_parking_spaces <dbl>, ## # total_of_special_requests <dbl>, reservation_status <chr>, reservation_status_date <date> ``` ] --- ## `slice` for certain row numbers .midi[ ```r # last five last_row <- nrow(hotels) # nrow() gives the number of rows in a data frame hotels %>% * slice((last_row - 4):last_row) ``` ``` ## # A tibble: 5 x 32 ## hotel is_canceled lead_time arrival_date_ye… arrival_date_mo… arrival_date_we… arrival_date_da… ## <chr> <dbl> <dbl> <dbl> <chr> <dbl> <dbl> ## 1 City… 0 23 2017 August 35 30 ## 2 City… 0 102 2017 August 35 31 ## 3 City… 0 34 2017 August 35 31 ## 4 City… 0 109 2017 August 35 31 ## 5 City… 0 205 2017 August 35 29 ## # … with 25 more variables: stays_in_weekend_nights <dbl>, stays_in_week_nights <dbl>, ## # adults <dbl>, children <dbl>, babies <dbl>, meal <chr>, country <chr>, market_segment <chr>, ## # distribution_channel <chr>, is_repeated_guest <dbl>, previous_cancellations <dbl>, ## # previous_bookings_not_canceled <dbl>, reserved_room_type <chr>, assigned_room_type <chr>, ## # booking_changes <dbl>, deposit_type <chr>, agent <chr>, company <chr>, ## # days_in_waiting_list <dbl>, customer_type <chr>, adr <dbl>, required_car_parking_spaces <dbl>, ## # total_of_special_requests <dbl>, reservation_status <chr>, reservation_status_date <date> ``` ] --- ## `filter` to select a subset of rows .midi[ ```r # bookings in City Hotels hotels %>% * filter(hotel == "City Hotel") ``` ``` ## # A tibble: 79,330 x 32 ## hotel is_canceled lead_time arrival_date_ye… arrival_date_mo… arrival_date_we… arrival_date_da… ## <chr> <dbl> <dbl> <dbl> <chr> <dbl> <dbl> ## 1 City… 0 6 2015 July 27 1 ## 2 City… 1 88 2015 July 27 1 ## 3 City… 1 65 2015 July 27 1 ## 4 City… 1 92 2015 July 27 1 ## 5 City… 1 100 2015 July 27 2 ## 6 City… 1 79 2015 July 27 2 ## # … with 79,324 more rows, and 25 more variables: stays_in_weekend_nights <dbl>, ## # stays_in_week_nights <dbl>, adults <dbl>, children <dbl>, babies <dbl>, meal <chr>, ## # country <chr>, market_segment <chr>, distribution_channel <chr>, is_repeated_guest <dbl>, ## # previous_cancellations <dbl>, previous_bookings_not_canceled <dbl>, reserved_room_type <chr>, ## # assigned_room_type <chr>, booking_changes <dbl>, deposit_type <chr>, agent <chr>, ## # company <chr>, days_in_waiting_list <dbl>, customer_type <chr>, adr <dbl>, ## # required_car_parking_spaces <dbl>, total_of_special_requests <dbl>, reservation_status <chr>, ## # reservation_status_date <date> ``` ] --- ## `filter` for many conditions at once ```r hotels %>% filter( * adults == 0, * children >= 1 ) %>% select(adults, babies, children) ``` ``` ## # A tibble: 223 x 3 ## adults babies children ## <dbl> <dbl> <dbl> ## 1 0 0 3 ## 2 0 0 2 ## 3 0 0 2 ## 4 0 0 2 ## 5 0 0 2 ## 6 0 0 3 ## # … with 217 more rows ``` --- ## `filter` for more complex conditions ```r # bookings with no adults and some children or babies in the room hotels %>% filter( adults == 0, * children >= 1 | babies >= 1 # | means or ) %>% select(adults, babies, children) ``` ``` ## # A tibble: 223 x 3 ## adults babies children ## <dbl> <dbl> <dbl> ## 1 0 0 3 ## 2 0 0 2 ## 3 0 0 2 ## 4 0 0 2 ## 5 0 0 2 ## 6 0 0 3 ## # … with 217 more rows ``` --- ## Logical operators in R <br> operator | definition || operator | definition ------------|------------------------------||--------------|---------------- `<` | less than ||`x` | `y` | `x` OR `y` `<=` | less than or equal to ||`is.na(x)` | test if `x` is `NA` `>` | greater than ||`!is.na(x)` | test if `x` is not `NA` `>=` | greater than or equal to ||`x %in% y` | test if `x` is in `y` `==` | exactly equal to ||`!(x %in% y)` | test if `x` is not in `y` `!=` | not equal to ||`!x` | not `x` `x & y` | `x` AND `y` || | --- .your-turn[ - Go to RStudio Cloud and start the second assignment: `03 - Wrangle Data` - Open the first R Markdown file: `hotels.Rmd` - Knit the document, and work on Exercises 1 - 4 ] <div class="countdown" id="timer_5e919760" style="right:0;bottom:0;" data-warnwhen="0"> <code class="countdown-time"><span class="countdown-digits minutes">15</span><span class="countdown-digits colon">:</span><span class="countdown-digits seconds">00</span></code> </div> .footnote[ RStudio Cloud workspace for this bootcamp is at [rstd.io/bootcamper-cloud](https://rstd.io/bootcamper-cloud). ] --- ## `distinct` to filter for unique rows ... and `arrange` to order alphabetically .small[ .pull-left[ ```r hotels %>% * distinct(market_segment) %>% arrange(market_segment) ``` ``` ## # A tibble: 8 x 1 ## market_segment ## <chr> ## 1 Aviation ## 2 Complementary ## 3 Corporate ## 4 Direct ## 5 Groups ## 6 Offline TA/TO ## 7 Online TA ## 8 Undefined ``` ] .pull-right[ ```r hotels %>% * distinct(hotel, market_segment) %>% arrange(hotel, market_segment) ``` ``` ## # A tibble: 14 x 2 ## hotel market_segment ## <chr> <chr> ## 1 City Hotel Aviation ## 2 City Hotel Complementary ## 3 City Hotel Corporate ## 4 City Hotel Direct ## 5 City Hotel Groups ## 6 City Hotel Offline TA/TO ## 7 City Hotel Online TA ## 8 City Hotel Undefined ## 9 Resort Hotel Complementary ## 10 Resort Hotel Corporate ## 11 Resort Hotel Direct ## 12 Resort Hotel Groups ## 13 Resort Hotel Offline TA/TO ## 14 Resort Hotel Online TA ``` ] ] --- ## `count` to create frequency tables .pull-left[ ```r # alphabetical order by default hotels %>% * count(market_segment) ``` ``` ## # A tibble: 8 x 2 ## market_segment n ## * <chr> <int> ## 1 Aviation 237 ## 2 Complementary 743 ## 3 Corporate 5295 ## 4 Direct 12606 ## 5 Groups 19811 ## 6 Offline TA/TO 24219 ## 7 Online TA 56477 ## 8 Undefined 2 ``` ] -- .pull-right[ ```r # descending frequency order hotels %>% * count(market_segment, sort = TRUE) ``` ``` ## # A tibble: 8 x 2 ## market_segment n ## * <chr> <int> ## 1 Online TA 56477 ## 2 Offline TA/TO 24219 ## 3 Groups 19811 ## 4 Direct 12606 ## 5 Corporate 5295 ## 6 Complementary 743 ## 7 Aviation 237 ## 8 Undefined 2 ``` ] --- ## `count` and `arrange` .pull-left[ ```r # ascending frequency order hotels %>% count(market_segment) %>% * arrange(n) ``` ``` ## # A tibble: 8 x 2 ## market_segment n ## <chr> <int> ## 1 Undefined 2 ## 2 Aviation 237 ## 3 Complementary 743 ## 4 Corporate 5295 ## 5 Direct 12606 ## 6 Groups 19811 ## 7 Offline TA/TO 24219 ## 8 Online TA 56477 ``` ] .pull-right[ ```r # descending frequency order # just like adding sort = TRUE hotels %>% count(market_segment) %>% * arrange(desc(n)) ``` ``` ## # A tibble: 8 x 2 ## market_segment n ## <chr> <int> ## 1 Online TA 56477 ## 2 Offline TA/TO 24219 ## 3 Groups 19811 ## 4 Direct 12606 ## 5 Corporate 5295 ## 6 Complementary 743 ## 7 Aviation 237 ## 8 Undefined 2 ``` ] --- ## `count` for multiple variables ```r hotels %>% * count(hotel, market_segment) ``` ``` ## # A tibble: 14 x 3 ## hotel market_segment n ## * <chr> <chr> <int> ## 1 City Hotel Aviation 237 ## 2 City Hotel Complementary 542 ## 3 City Hotel Corporate 2986 ## 4 City Hotel Direct 6093 ## 5 City Hotel Groups 13975 ## 6 City Hotel Offline TA/TO 16747 ## 7 City Hotel Online TA 38748 ## 8 City Hotel Undefined 2 ## 9 Resort Hotel Complementary 201 ## 10 Resort Hotel Corporate 2309 ## 11 Resort Hotel Direct 6513 ## 12 Resort Hotel Groups 5836 ## 13 Resort Hotel Offline TA/TO 7472 ## 14 Resort Hotel Online TA 17729 ``` --- ## order matters when you `count` .midi[ .pull-left[ ```r # hotel type first hotels %>% * count(hotel, market_segment) ``` ``` ## # A tibble: 14 x 3 ## hotel market_segment n ## * <chr> <chr> <int> ## 1 City Hotel Aviation 237 ## 2 City Hotel Complementary 542 ## 3 City Hotel Corporate 2986 ## 4 City Hotel Direct 6093 ## 5 City Hotel Groups 13975 ## 6 City Hotel Offline TA/TO 16747 ## 7 City Hotel Online TA 38748 ## 8 City Hotel Undefined 2 ## 9 Resort Hotel Complementary 201 ## 10 Resort Hotel Corporate 2309 ## 11 Resort Hotel Direct 6513 ## 12 Resort Hotel Groups 5836 ## 13 Resort Hotel Offline TA/TO 7472 ## 14 Resort Hotel Online TA 17729 ``` ] .pull-right[ ```r # market segment first hotels %>% * count(market_segment, hotel) ``` ``` ## # A tibble: 14 x 3 ## market_segment hotel n ## * <chr> <chr> <int> ## 1 Aviation City Hotel 237 ## 2 Complementary City Hotel 542 ## 3 Complementary Resort Hotel 201 ## 4 Corporate City Hotel 2986 ## 5 Corporate Resort Hotel 2309 ## 6 Direct City Hotel 6093 ## 7 Direct Resort Hotel 6513 ## 8 Groups City Hotel 13975 ## 9 Groups Resort Hotel 5836 ## 10 Offline TA/TO City Hotel 16747 ## 11 Offline TA/TO Resort Hotel 7472 ## 12 Online TA City Hotel 38748 ## 13 Online TA Resort Hotel 17729 ## 14 Undefined City Hotel 2 ``` ] ] --- .your-turn[ - Go to RStudio Cloud and start the second assignment: `03 - Wrangle Data` - Open the first R Markdown file: `hotels.Rmd` - Knit the document, and work on Exercises 5 and 6. ] <div class="countdown" id="timer_5e919757" style="right:0;bottom:0;" data-warnwhen="0"> <code class="countdown-time"><span class="countdown-digits minutes">10</span><span class="countdown-digits colon">:</span><span class="countdown-digits seconds">00</span></code> </div> .footnote[ RStudio Cloud workspace for this bootcamp is at [rstd.io/bootcamper-cloud](https://rstd.io/bootcamper-cloud). ] --- ## `mutate` to add a new variable ```r hotels %>% * mutate(little_ones = children + babies) %>% select(children, babies, little_ones) %>% arrange(desc(little_ones)) ``` ``` ## # A tibble: 119,390 x 3 ## children babies little_ones ## <dbl> <dbl> <dbl> ## 1 10 0 10 ## 2 0 10 10 ## 3 0 9 9 ## 4 2 1 3 ## 5 2 1 3 ## 6 2 1 3 ## # … with 119,384 more rows ``` --- ## Little ones in resort and city hotels .midi[ .pull-left[ ```r # Resort Hotel hotels %>% mutate(little_ones = children + babies) %>% filter( little_ones >= 1, hotel == "Resort Hotel" ) %>% select(hotel, little_ones) ``` ``` ## # A tibble: 3,929 x 2 ## hotel little_ones ## <chr> <dbl> ## 1 Resort Hotel 1 ## 2 Resort Hotel 2 ## 3 Resort Hotel 2 ## 4 Resort Hotel 2 ## 5 Resort Hotel 1 ## 6 Resort Hotel 1 ## # … with 3,923 more rows ``` ] .pull-right[ ```r # City Hotel hotels %>% mutate(little_ones = children + babies) %>% filter( little_ones > 1, hotel == "City Hotel" ) %>% select(hotel, little_ones) ``` ``` ## # A tibble: 2,140 x 2 ## hotel little_ones ## <chr> <dbl> ## 1 City Hotel 2 ## 2 City Hotel 2 ## 3 City Hotel 2 ## 4 City Hotel 2 ## 5 City Hotel 2 ## 6 City Hotel 2 ## # … with 2,134 more rows ``` ] ] --- .discussion[ What is happening in the following chunk? ] .midi[ ```r hotels %>% mutate(little_ones = children + babies) %>% count(hotel, little_ones) %>% mutate(prop = n / sum(n)) ``` ``` ## # A tibble: 12 x 4 ## hotel little_ones n prop ## * <chr> <dbl> <int> <dbl> ## 1 City Hotel 0 73923 0.619 ## 2 City Hotel 1 3263 0.0273 ## 3 City Hotel 2 2056 0.0172 ## 4 City Hotel 3 82 0.000687 ## 5 City Hotel 9 1 0.00000838 ## 6 City Hotel 10 1 0.00000838 ## 7 City Hotel NA 4 0.0000335 ## 8 Resort Hotel 0 36131 0.303 ## 9 Resort Hotel 1 2183 0.0183 ## 10 Resort Hotel 2 1716 0.0144 ## 11 Resort Hotel 3 29 0.000243 ## 12 Resort Hotel 10 1 0.00000838 ``` ] --- # `summarise` for summary stats ```r # mean average daily rate for all bookings hotels %>% * summarise(mean_adr = mean(adr)) ``` ``` ## # A tibble: 1 x 1 ## mean_adr ## <dbl> ## 1 102. ``` -- <br> .tip[ `summarise()` changes the data frame entirely, it collapses rows down to a single summary statistics, and removes all columns that are irrelevant to the calculation. ] --- .tip[ `summarise()` also lets you get away with being sloppy and not naming your new column, but that's not recommended! ] .midi[ ❌ ```r hotels %>% summarise(mean(adr)) ``` ``` ## # A tibble: 1 x 1 ## `mean(adr)` ## <dbl> ## 1 102. ``` ✅ ```r hotels %>% summarise(mean_adr = mean(adr)) ``` ``` ## # A tibble: 1 x 1 ## mean_adr ## <dbl> ## 1 102. ``` ] --- # `group_by` for grouped operations ```r # mean average daily rate for all booking at city and resort hotels hotels %>% * group_by(hotel) %>% summarise(mean_adr = mean(adr)) ``` ``` ## # A tibble: 2 x 2 ## hotel mean_adr ## * <chr> <dbl> ## 1 City Hotel 105. ## 2 Resort Hotel 95.0 ``` --- ## Calculating frequencies The following two give the same result, so `count` is simply short for `group_by` then determine frequencies .pull-left[ ```r hotels %>% group_by(hotel) %>% summarise(n = n()) ``` ``` ## # A tibble: 2 x 2 ## hotel n ## * <chr> <int> ## 1 City Hotel 79330 ## 2 Resort Hotel 40060 ``` ] .pull-right[ ```r hotels %>% count(hotel) ``` ``` ## # A tibble: 2 x 2 ## hotel n ## * <chr> <int> ## 1 City Hotel 79330 ## 2 Resort Hotel 40060 ``` ] --- # Multiple summary statistics `summarise` can be used for multiple summary statistics as well ```r hotels %>% summarise( min_adr = min(adr), mean_adr = mean(adr), median_adr = median(adr), max_adr = max(adr) ) ``` ``` ## # A tibble: 1 x 4 ## min_adr mean_adr median_adr max_adr ## <dbl> <dbl> <dbl> <dbl> ## 1 -6.38 102. 94.6 5400 ``` --- .your-turn[ - Go to RStudio Cloud and start the second assignment: `03 - Wrangle Data` - Open the first R Markdown file: `hotels.Rmd` - Knit the document and work on the Exercises 7 and 8. ] <div class="countdown" id="timer_5e9196b4" style="right:0;bottom:0;" data-warnwhen="0"> <code class="countdown-time"><span class="countdown-digits minutes">10</span><span class="countdown-digits colon">:</span><span class="countdown-digits seconds">00</span></code> </div> .footnote[ RStudio Cloud workspace for this bootcamp is at [rstd.io/bootcamper-cloud](https://rstd.io/bootcamper-cloud). ]