2 Import
This chapter includes the following recipes:
- Import data quickly with a GUI
- Read a comma-separated values (csv) file
- Read a semi-colon delimited file
- Read a tab delimited file
- Read a text file with an unusual delimiter
- Read a fixed-width file
- Read a file no header
- Skip lines at the start of a file when reading a file
- Skip lines at the end of a file when reading a file
- Replace missing values as you read a file
- Read a compressed RDS file
- Read an Excel spreadsheet
- Read a specific sheet from an Excel spreadsheet
- Read a field of cells from an excel spreadsheet
- Write to a comma-separate values (csv) file
- Write to a semi-colon delimited file
- Write to a tab-delimited file
- Write to a text file with arbitrary delimiters
- Write to a compressed RDS file
What you should know before you begin
Before you can manipulate data with R, you need to import the data into R’s memory, or build a connection to the data that R can use to access the data remotely. For example, you can build a connection to data that lives in a database.
How you import your data will depend on the format of the data. The most common way to store small data sets is as a plain text file. Data may also be stored in a proprietary format associated with a specific piece of software, such as SAS, SPSS, or Microsoft Excel. Data used on the internet is often stored as a JSON or XML file. Large data sets may be stored in a database or a distributed storage system.
When you import data into R, R stores the data in your computer’s RAM while you manipulate it. This creates a size limitation: truly big data sets should be stored outside of R in a database or a distributed storage system. You can then create a connection to the system that R can use to access the data without bringing the data into your computer’s RAM.
The readr package contains the most common functions in the tidyverse for importing data. The readr package is loaded when you run library(tidyverse). The tidyverse also includes the following packages for importing specific types of data. These are not loaded with library(tidyverse). You must load them individually when you need them.
- DBI - connect to databases
- haven - read SPSS, Stata, or SAS data
- httr - access data over web APIs
- jsonlite - read JSON
- readxl - read Excel spreadsheets
- rvest - scrape data from the web
- xml2 - read XML
The working directory
Reading and writing files often involves the use of file paths. If you pass R a partial file path, R will append it to the end of the file path that leads to your working directory. In other words, partial file paths are interpretted in relation to your working directory. The working directory can change from session to session, as a general rule, the working directory is the directory where:
- Your .Rmd file lives (if you are running code by knitting the document)
- Your .Rproj file lives (if you are using the RStudio Project system)
- You opened the R interpreter from (if you are using a unix terminal/shell window)
getwd() to see the file path that leads to your current working directory.
2.1 Import data quickly with a GUI
You want to import data quickly, and you do not mind using a semi-reproducible graphical user interface (GUI) to do so. Your data is not so big that it needs to stay in a database or external storage system.
Solution
Discussion
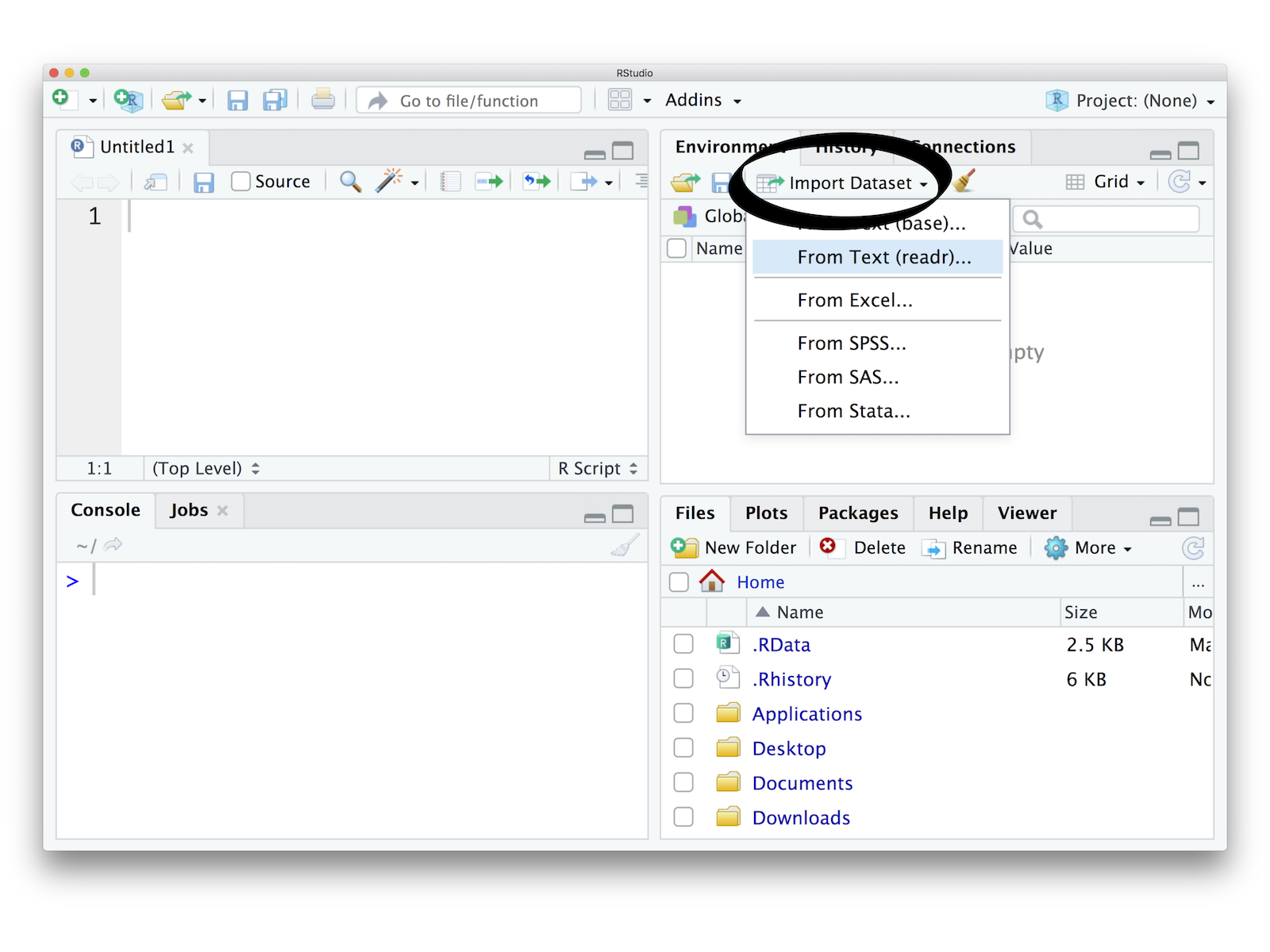
The RStudio IDE provides an Import Dataset button in the Environment pane, which appears in the top right corner of the IDE by default. You can use this button to import data that is stored in plain text files as well as in Excel, SAS, SPSS, and Stata files.
Click the button to launch a window that includes a file browser (below). Use the browser to select the file to import.
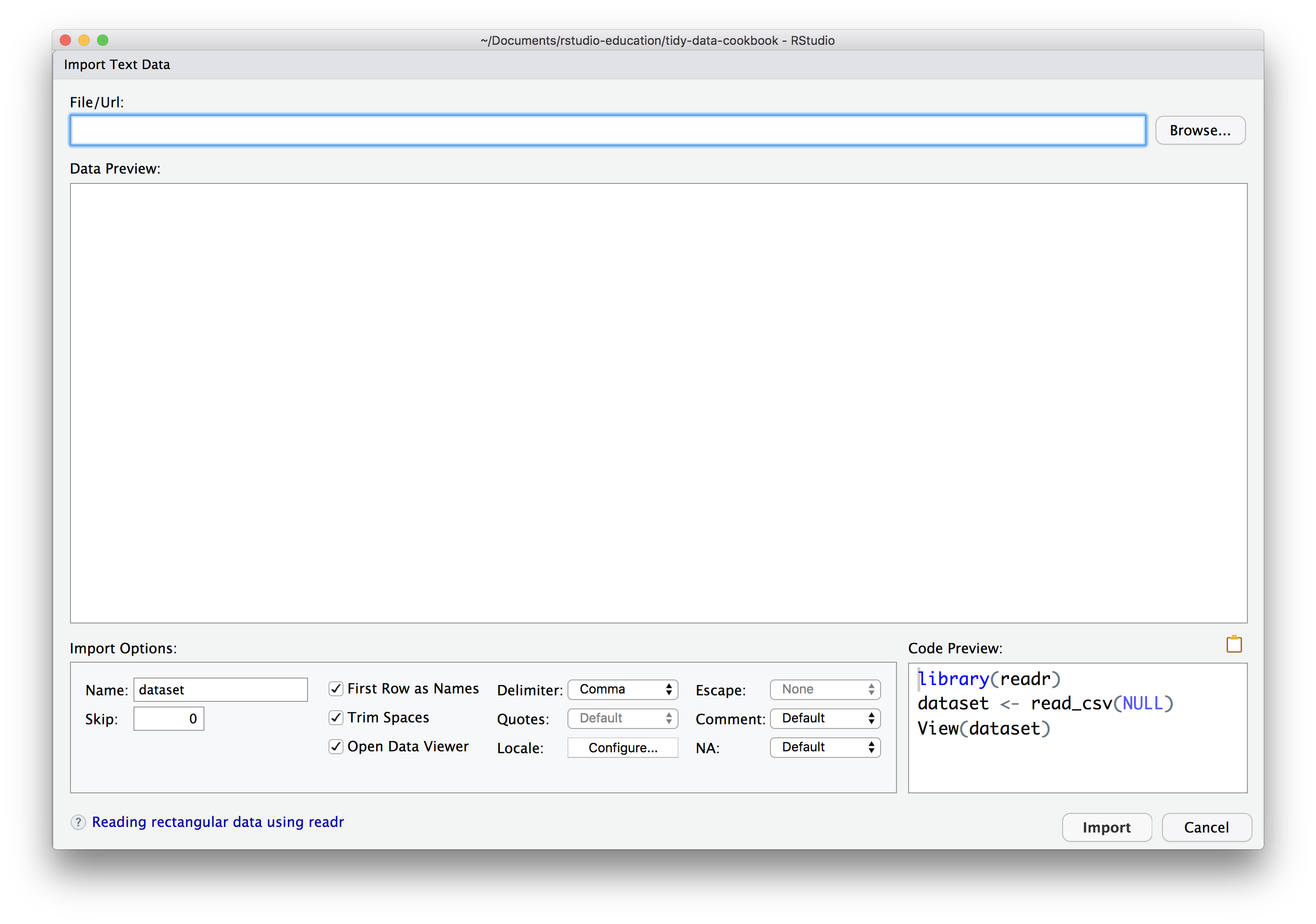
After you’ve selected a file, RStudio will display a preview of how the file will be imported as a data frame. Below the preview, RStudio provides a GUI interface to the common options for importing the type of file you have selected. As you customize the options, RStudio updates the data preview to display the results.
The bottom right-hand corner of the window displays R code that, if run, will reproduce your importation process programatically. You should copy and save this code if you wish to document your work in a reproducible workflow.
2.2 Read a comma-separated values (csv) file
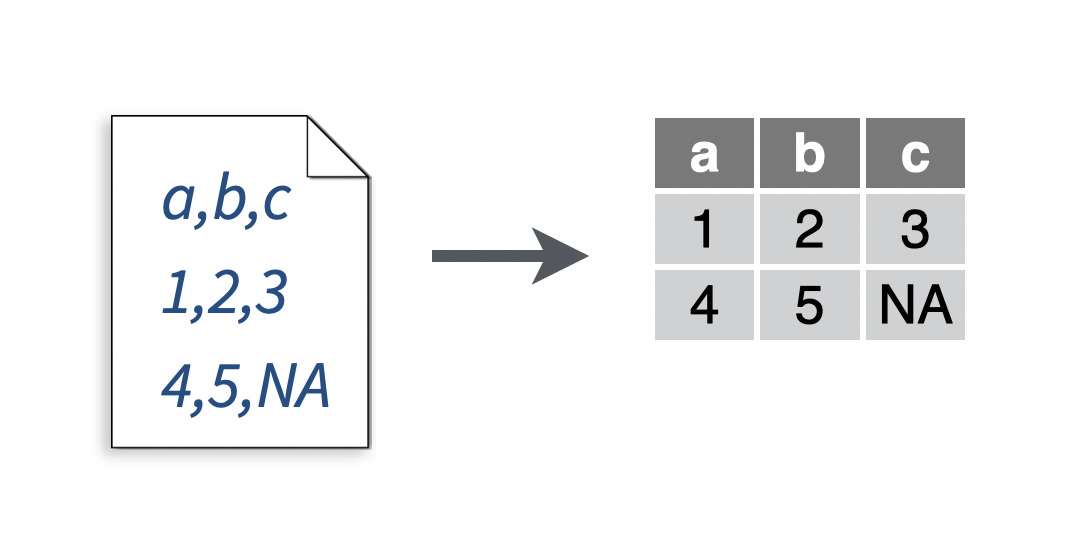
You want to read a .csv file.
Solution
# To make a .csv file to read
write_file(x = "a,b,c\n1,2,3\n4,5,NA", path = "file.csv")
my_data <- read_csv("file.csv")## Parsed with column specification:
## cols(
## a = col_double(),
## b = col_double(),
## c = col_double()
## )## # A tibble: 2 x 3
## a b c
## <dbl> <dbl> <dbl>
## 1 1 2 3
## 2 4 5 NADiscussion
Comma separated value (.csv) files are plain text files arranged so that each line contains a row of data and each cell within a line is separated by a comma. Most data analysis software can export their data as .csv files. So if you are in a pinch you can usually export data from a program as a .csv and then read it into R.
You can also use read_csv() to import csv files that are hosted at their own unique URL. This only works if you are connected to the internet, e.g.
2.3 Read a semi-colon delimited file
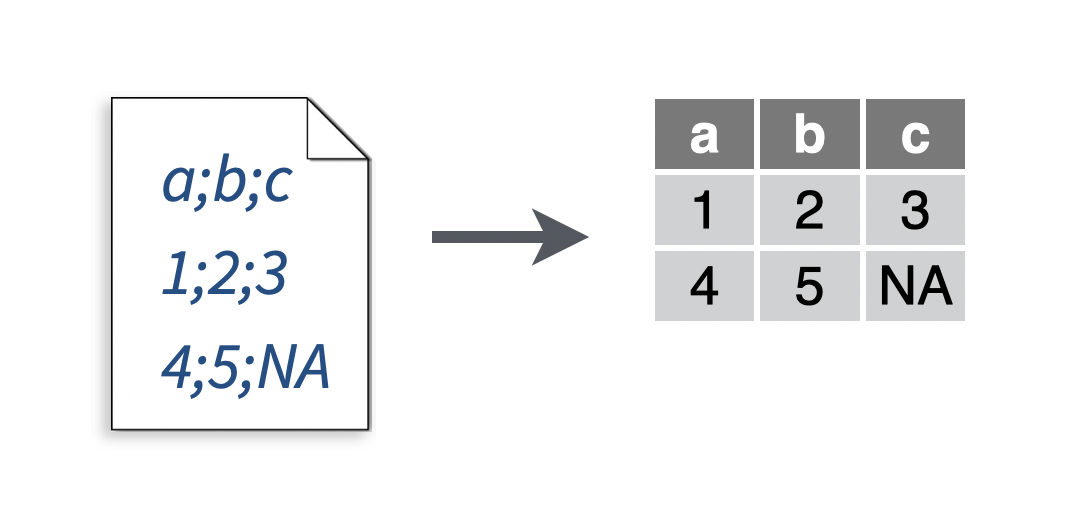
You want to read a file that resembles a csv, but uses a semi-colon to separate cells.
Solution
# To make a .csv file to read
write_file(x = "a;b;c\n1;2;3\n4;5;NA", path = "file2.csv")
my_data <- read_csv2("file2.csv")## Using ',' as decimal and '.' as grouping mark. Use read_delim() for more control.## Parsed with column specification:
## cols(
## a = col_double(),
## b = col_double(),
## c = col_double()
## )## # A tibble: 2 x 3
## a b c
## <dbl> <dbl> <dbl>
## 1 1 2 3
## 2 4 5 NADiscussion
Semi-colon delimited files are popular in parts of the world that use commas for decimal places, like Europe. Semi-colon delimited files are often still given the .csv file extension.
2.4 Read a tab delimited file
You want to read a file that resembles a csv, but uses a tab to separate cells.
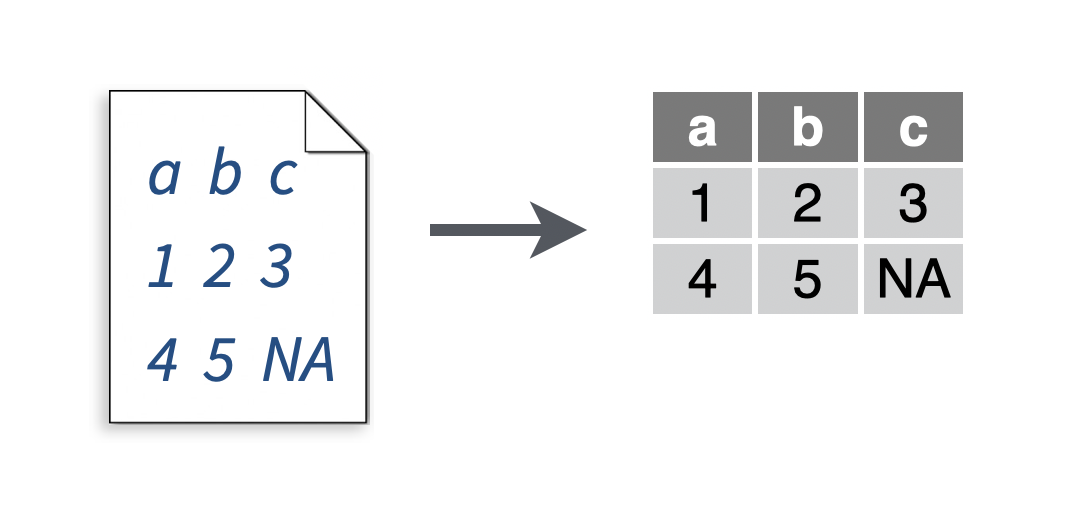
Solution
# To make a .tsv file to read
write_file(x = "a\tb\tc\n1\t2\t3\n4\t5\tNA", path = "file.tsv")
my_data <- read_tsv("file.tsv")## Parsed with column specification:
## cols(
## a = col_double(),
## b = col_double(),
## c = col_double()
## )## # A tibble: 2 x 3
## a b c
## <dbl> <dbl> <dbl>
## 1 1 2 3
## 2 4 5 NADiscussion
Tab delimited files are text files that place each row of a table in its own line, and separate each cell within a line with a tab. Tab delimited files commonly have the extensions .tab, .tsv, and .txt.
2.5 Read a text file with an unusual delimiter
You want to read a file that resembles a csv, but uses something other than a comma to separate cells.
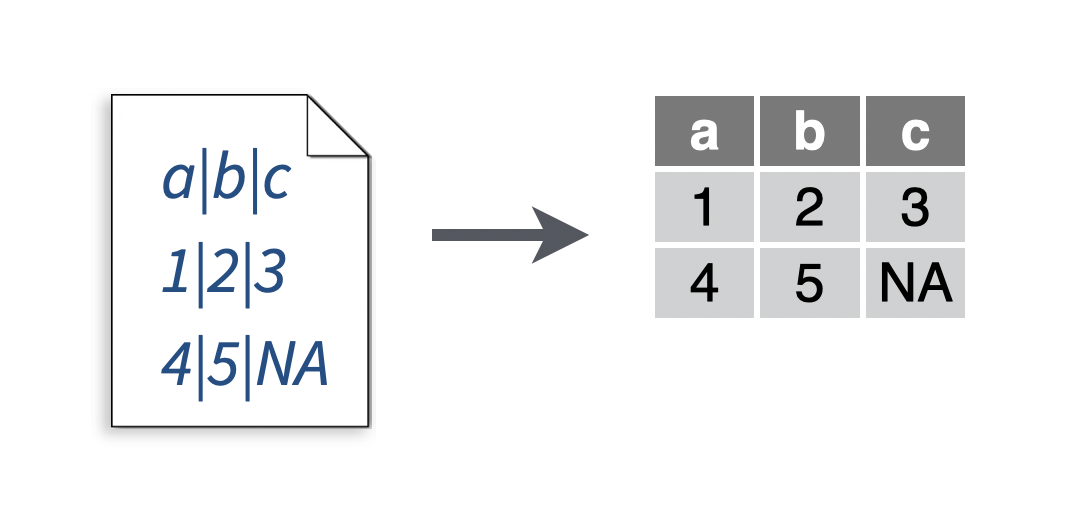
Solution
# To make a file to read
write_file(x = "a|b|c\n1|2|3\n4|5|NA", path = "file.txt")
my_data <- read_delim("file.txt", delim = "|")## Parsed with column specification:
## cols(
## a = col_double(),
## b = col_double(),
## c = col_double()
## )## # A tibble: 2 x 3
## a b c
## <dbl> <dbl> <dbl>
## 1 1 2 3
## 2 4 5 NADiscussion
Use read_delim() as you would read_csv(). Pass the delimiter that your file uses as a character string to the delim argument of read_delim().
2.6 Read a fixed-width file
You want to read a .fwf file, which uses the fixed width format to represent a table (each column begins \(n\) spaces from the left for every line).
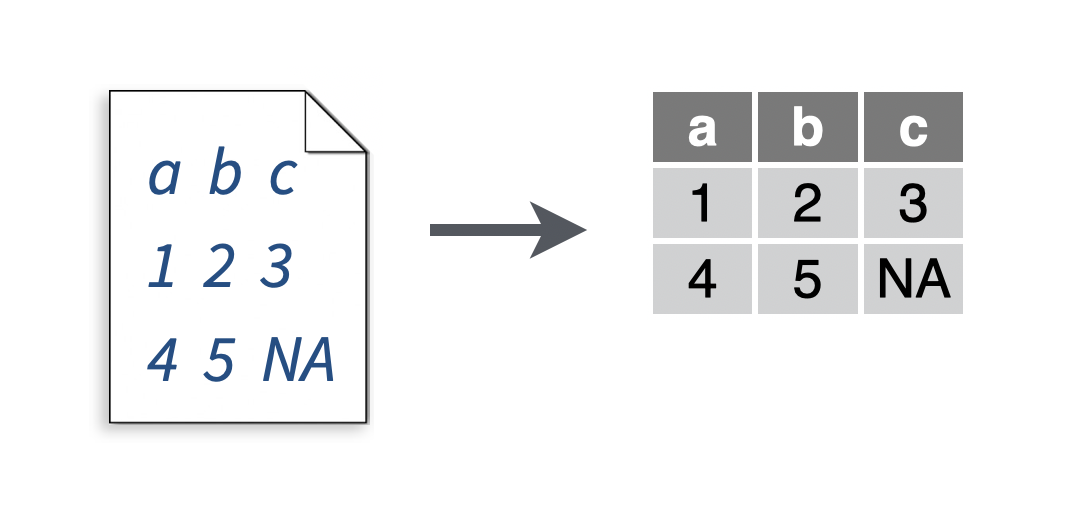
Solution
# To make a .fwf file to read
write_file(x = "a b c\n1 2 3\n4 5 NA", path = "file.fwf")
my_data <- read_table("file.fwf")## Parsed with column specification:
## cols(
## a = col_double(),
## b = col_double(),
## c = col_double()
## )## # A tibble: 2 x 3
## a b c
## <dbl> <dbl> <dbl>
## 1 1 2 3
## 2 4 5 NADiscussion
Fixed width files arrange data so that each row of a table is in its own line, and each cell begins at a fixed number of character spaces from the beginning of the line. For example, in the example below, the cells in the second column each begin 20 spaces from the beginning of the line, no matter many spaces the contents of the first cell required. At first glance, it is easy to mistake fixed width files for tab delimited files. Fixed with files use individual spaces to separate cells, and not tabs.
John Smith WA 418-Y11-4111
Mary Hartford CA 319-Z19-4341
Evan Nolan IL 219-532-c301read_table() will read fixed-width files where each column is separated by at least one whitespace on every line. Use read_fwf() to read fixed-width files that have non-standard formatting.
2.7 Read a file no header
You want to read a file that does not include a line of column names at the start of the file.
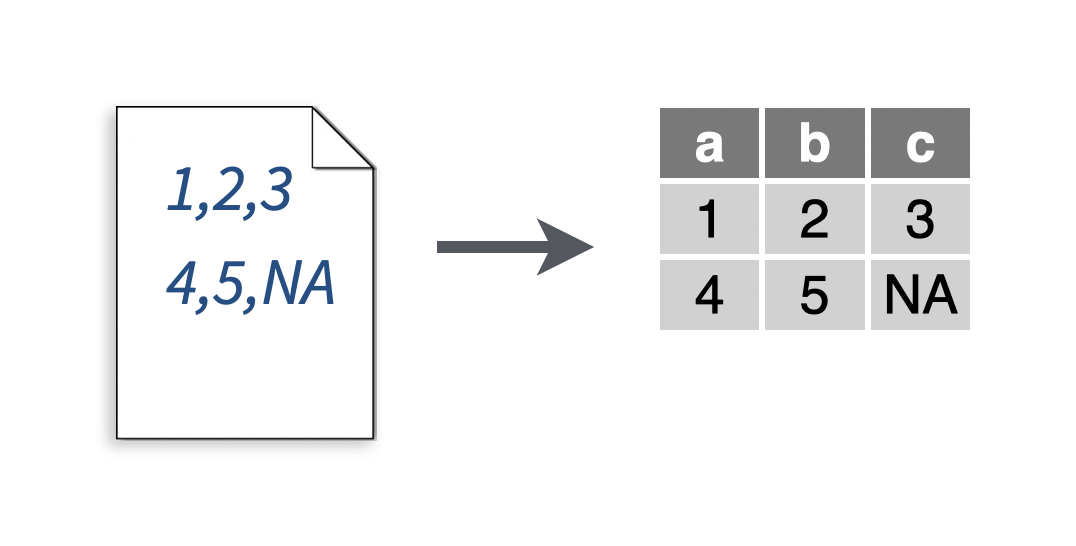
Solution
# To make a .csv file to read
write_file("1,2,3\n4,5,NA","file.csv")
my_data <- read_csv("file.csv", col_names = c("a", "b", "c"))## Parsed with column specification:
## cols(
## a = col_double(),
## b = col_double(),
## c = col_double()
## )## # A tibble: 2 x 3
## a b c
## <dbl> <dbl> <dbl>
## 1 1 2 3
## 2 4 5 NADiscussion
If you do not wish to supply column names, set col_names = FALSE. The col_names argument works for all readr functions that read tabular data.
2.8 Skip lines at the start of a file when reading a file
You want to read a portion of a file, skipping one or more lines at the start of the file. For example, you want to avoid reading the introductory text at the start of a file.
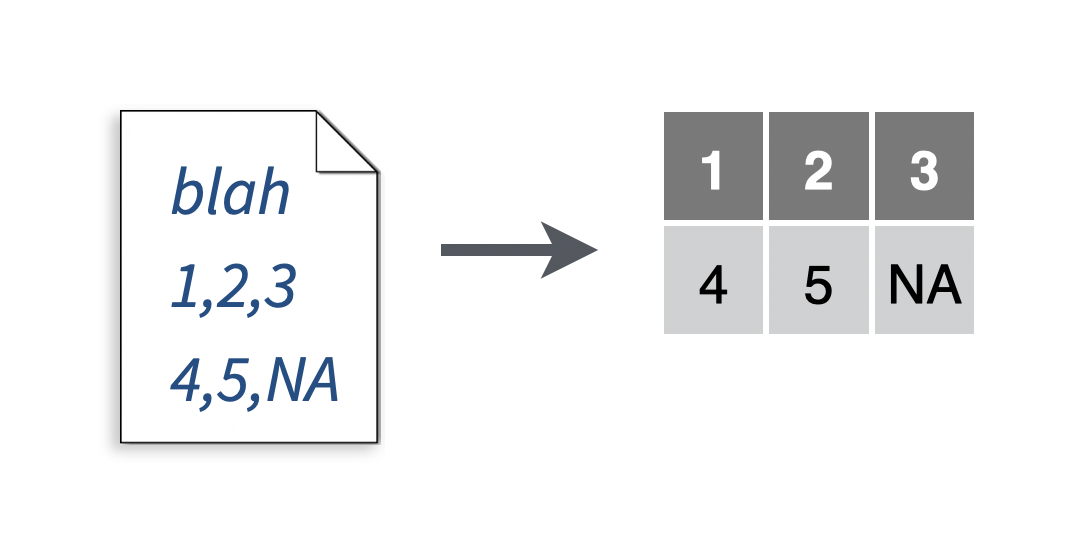
Solution
# To make a .csv file to read
write_file("a,b,c\n1,2,3\n4,5,NA","file.csv")
my_data <- read_csv("file.csv", skip = 1)## Parsed with column specification:
## cols(
## `1` = col_double(),
## `2` = col_double(),
## `3` = col_logical()
## )## # A tibble: 1 x 3
## `1` `2` `3`
## <dbl> <dbl> <lgl>
## 1 4 5 NADiscussion
Set skip equal to the number of lines you wish to skip before you begin reading the file. The skip argument works for all readr functions that read tabular data, and can be combined with the n_max argument to skip more lines at the end of a file.
When in doubt, first try reading the file with read_lines("file.csv") to determine how many lines you need to skip.
2.9 Skip lines at the end of a file when reading a file
You want to read a portion of a file, skipping one or more lines at the end of the file. For example, you want to avoid reading in a text comment that appears at the end of a file.
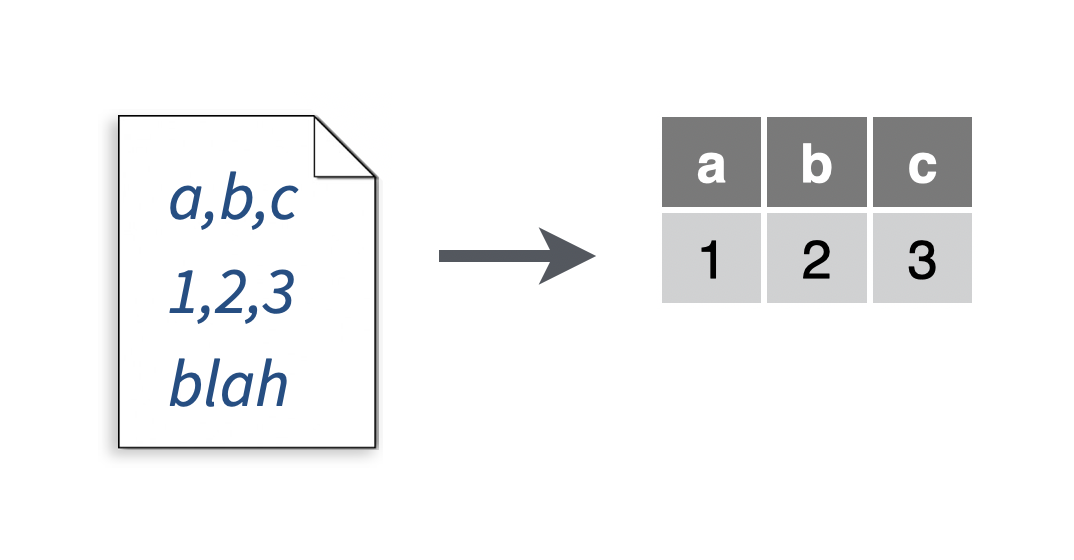
Solution
# To make a .csv file to read
write_file("a,b,c\n1,2,3\n4,5,NA","file.csv")
my_data <- read_csv("file.csv", n_max = 1)## Parsed with column specification:
## cols(
## a = col_double(),
## b = col_double(),
## c = col_double()
## )## # A tibble: 1 x 3
## a b c
## <dbl> <dbl> <dbl>
## 1 1 2 3Discussion
Set n_max equal to the number of non-header lines you wish to read before you stop reading lines. The n_max argument works for all readr functions that read tabular data.
When in doubt, first try reading the file with read_lines("file.csv") to determine how many lines you need to skip.
2.10 Replace missing values as you read a file
You want to convert missing values to NA as you read a file, because they have been recorded with a different symbol.
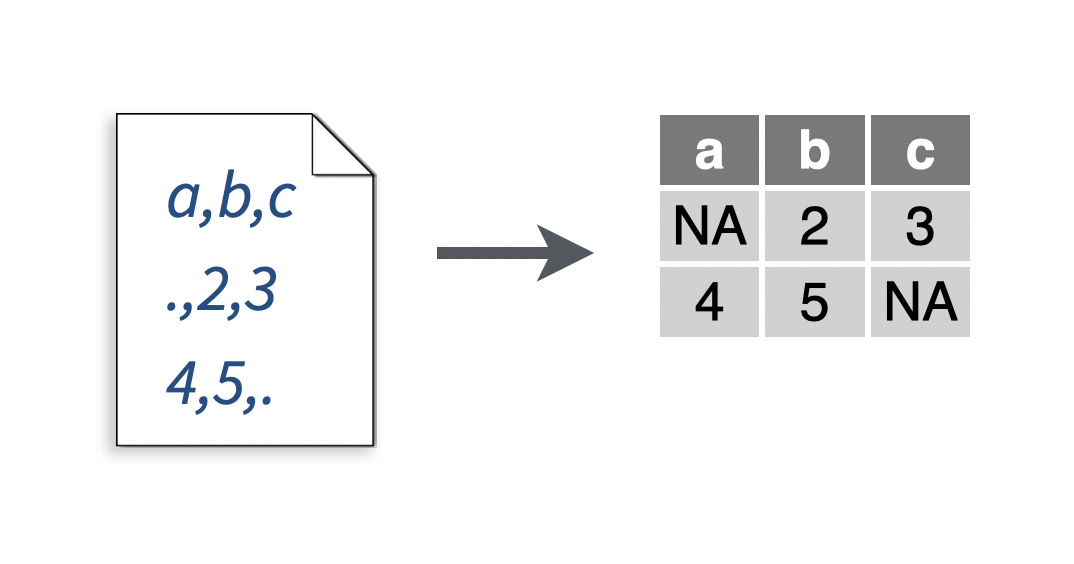
Solution
# To make a .csv file to read
write_file("a,b,c\n1,2,3\n4,5,.","file.csv")
my_data <- read_csv("file.csv", na = ".")## Parsed with column specification:
## cols(
## a = col_double(),
## b = col_double(),
## c = col_double()
## )## # A tibble: 2 x 3
## a b c
## <dbl> <dbl> <dbl>
## 1 1 2 3
## 2 4 5 NADiscussion
R’s uses the string NA to represent missing data. If your file was exported from another language or application, it might use a different convention. R is likely to read in the convention as a character string, failing to understand that it represents missing data. To prevent this, explicitly tell read_csv() which strings are used to represent missing data.
The na argument works for all readr functions that read tabular data.
2.11 Read a compressed RDS file
You want to read an .RDS file.
Solution
# To make a .RDS file to read
saveRDS(pressure, file = "file.RDS")
my_data <- readRDS("file.RDS")
my_data## temperature pressure
## 1 0 0.0002
## 2 20 0.0012
## 3 40 0.0060
## 4 60 0.0300
## 5 80 0.0900
## 6 100 0.2700
## 7 120 0.7500
## 8 140 1.8500
## 9 160 4.2000
## 10 180 8.8000
## 11 200 17.3000
## 12 220 32.1000
## 13 240 57.0000
## 14 260 96.0000
## 15 280 157.0000
## 16 300 247.0000
## 17 320 376.0000
## 18 340 558.0000
## 19 360 806.0000Discussion
readRDS is a base R function—you do not need to run library(tidyverse) to use it. RDS is a file format native to R for saving compressed content. RDS files are not text files and are not human readable in their raw form. Each RDS file contains a single object, which makes it easy to assign its output directly to a single R object. This is not necessarily the case for .RData files, which makes .RDS files safer to use.
2.12 Read an Excel spreadsheet
You want to read an Excel spreadsheet.
Solution
library(readxl)
# File path to an example excel spreadsheet to import
file_path <- readxl_example("datasets.xlsx")
my_data <- read_excel(file_path)
my_data## # A tibble: 150 x 5
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## <dbl> <dbl> <dbl> <dbl> <chr>
## 1 5.1 3.5 1.4 0.2 setosa
## 2 4.9 3 1.4 0.2 setosa
## 3 4.7 3.2 1.3 0.2 setosa
## 4 4.6 3.1 1.5 0.2 setosa
## 5 5 3.6 1.4 0.2 setosa
## 6 5.4 3.9 1.7 0.4 setosa
## 7 4.6 3.4 1.4 0.3 setosa
## 8 5 3.4 1.5 0.2 setosa
## 9 4.4 2.9 1.4 0.2 setosa
## 10 4.9 3.1 1.5 0.1 setosa
## # … with 140 more rowsDiscussion
By default, read_excel() reads the first sheet in an Excel spreadsheet. See the next recipe to read in sheets other than the first.
read_excel() is loaded with the readxl package, which must be loaded with library(readxl). Pass read_excel() a file path or URL that leads to the Excel file you wish to read. readxl_example("datasets.xlsx") returns a file path that leads to an example Excel spreadsheet that is conveniently installed with the readxl package.
2.13 Read a specific sheet from an Excel spreadsheet
You want to read a specific sheet from an Excel spreadsheet.
Solution
library(readxl)
# File path to an example excel spreadsheet to import
file_path <- readxl_example("datasets.xlsx")
my_data <- read_excel(file_path, sheet = "chickwts")
my_data## # A tibble: 71 x 2
## weight feed
## <dbl> <chr>
## 1 179 horsebean
## 2 160 horsebean
## 3 136 horsebean
## 4 227 horsebean
## 5 217 horsebean
## 6 168 horsebean
## 7 108 horsebean
## 8 124 horsebean
## 9 143 horsebean
## 10 140 horsebean
## # … with 61 more rowsDiscussion
To read a specific sheet from a larger Excel spreadsheet, use the sheet argument to pass read_excel() the name of the sheet as a character string. You can also pass sheet the number of the sheet to read. For example, read_excel(file_path, sheet = 2) would read the second spreadsheet in the file.
If you are unsure of the name of a sheet, use the excel_sheets() function to list the names of the spreadsheets within a file, without importing the file, e.g. excel_sheets(file_path).
2.14 Read a field of cells from an excel spreadsheet
You want to read a subset of cells from an Excel spreadsheet.
Solution
library(readxl)
# File path to an example excel spreadsheet to import
file_path <- readxl_example("datasets.xlsx")
my_data <- read_excel(file_path, range = "C1:E4", skip = 3, n_max = 10)
my_data## # A tibble: 3 x 3
## Petal.Length Petal.Width Species
## <dbl> <dbl> <chr>
## 1 1.4 0.2 setosa
## 2 1.4 0.2 setosa
## 3 1.3 0.2 setosaDiscussion
read_excel() adopts the skip and [n_max][Skip lines at the end of a file when reading a file] arguments of reader functions to skip rows at the top of the spreadsheet and to control how far down the spreadsheet to read. Use therangeargument to specify a subset of columns to read. Two column names separated by a:` specifies those two columns and every column between them.
2.15 Write to a comma-separate values (csv) file
You want to save a tibble or data frame as a .csv file.
Discussion
write_csv() is about twice as fast as base R’s write.csv() and never adds rownames to a table. Tidyverse users tend to place important information in its own column, where it can be easily accessed, instead of in the rownames, where it cannot be as easily accessed.
R will save your file at the location described by appending the path argument to your working directory. If your path contains directories, these must exist before you run write_csv().
2.16 Write to a semi-colon delimited file
You want to save a tibble or data frame as a .csv file that uses semi-colons to delimit cells.
Discussion
R will save your file at the location described by appending the path argument to your working directory. If your path contains directories, these must exist before you run write_csv2().
2.17 Write to a tab-delimited file
You want to save a tibble or data frame as a tab delimited file.
Discussion
R will save your file at the location described by appending the path argument to your working directory. If your path contains directories, these must exist before you run write_tsv().
2.18 Write to a text file with arbitrary delimiters
You want to save a tibble or data frame as a plain text file that uses an unusual delimiter.
Discussion
write_delim() behaves like write_csv(), but requires a delim argument. Pass delim the delimiter you wish to use to separate cells, as a character string.
R will save your file at the location described by appending the path argument to your working directory. If your path contains directories, these must exist before you run write_delim().
2.19 Write to a compressed RDS file
You want to write a tibble or data frame to a .RDS file.
Solution
Discussion
saveRDS(), along with readRDS(), is a base R function, which explains the difference in the argument names as well as the read/write naming pattern compared to readr functions—take note!
R will save your file at the location described by appending the path argument to your working directory. If your path contains directories, these must exist before you run saveRDS(). Use the .RDS file extension in the file name to help make the uncommon file format obvious.